思享家丨遇事不决问专家,专家不在问 AI --- 生成式 AI 赋能企业全栈观察力(FSO)(一)
浏览量:1268 上传更新:2023-09-07
思科联天下 思科科技 2023-09-07 17:05 发表于浙江
思享家是一个介绍如何利用思科先进技术解决客户难题的栏目。每期聚焦一个技术热点或应用场景,邀请资深思科技术专家深入浅出地介绍,为读者提供实用性强的建议。
数字化转型推动了体验经济,用户的最终体验越来越成为企业核心竞争力的关键因素。但我们都知道一个 IT 系统是由各个技术栈堆叠构成,最终体验是这些单独体验的积累,所以如果没有一个全栈视野就很难掌控最终的体验效果,这就是思科提出全栈可观察力(Full-Stack Observability,FSO)概念的原因。但 FSO 的盛行带来了另一方面的挑战,一线运维,特别是第一级响应人员,一般都是技术领域相对专一的操作员,而全栈监测则要求不仅掌握全栈知识,还需要对各个领域工具所输出的指标都能深谙于心,才能第一时间做出正确决策,最大化降低体验恶化带来的业务影响。当然我们可以通过一个集成了全栈所有工具的看板缓解这个矛盾,但随着全栈监测的深入,场景越来越多、工具越来越复杂,看板变成了像旧式科幻片里的控制台,目之所及密密麻麻布满了看似先进的各式按钮和屏幕,但真是信息展示的越多问题定位的效率就越高吗?我们看看在新式的科幻片里是什么样的。无论是流浪地球的 MOSS 还是钢铁侠的贾维斯,都没有了眼花缭乱的按钮和屏幕,面对复杂局面做出快速决策的方式都是与强人工智能的自然语言交互。那么为什么不能在日常运维响应上也实现这种体验呢?这几期连载我们就来讨论如何构建这样的全栈运维 “贾维斯”。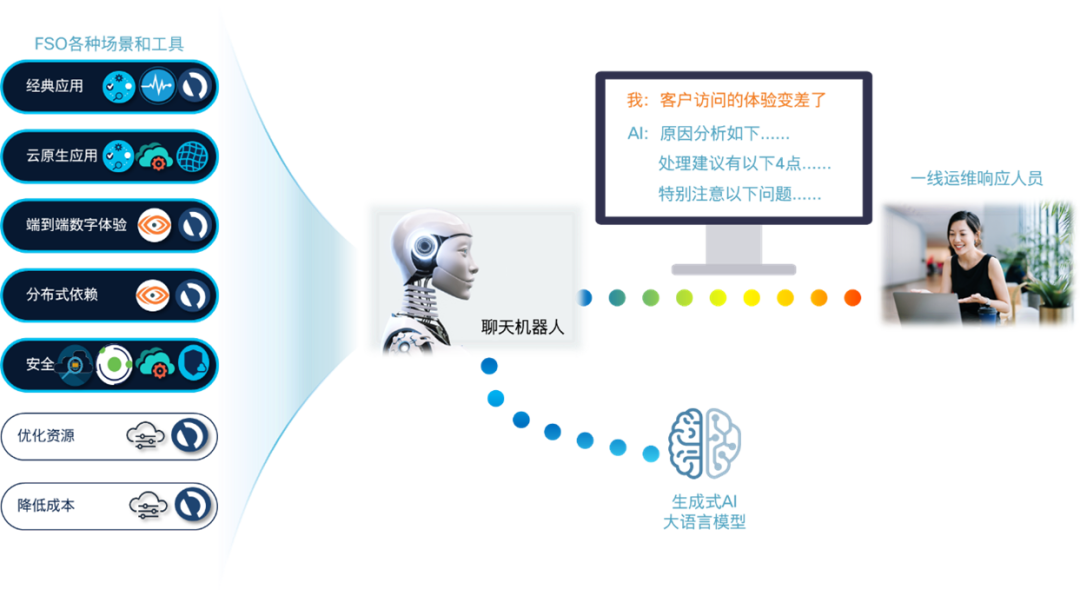
首先的问题是 AI 的智能能否胜任这样的全栈架构师的职责。在以 ChatGPT 为首的生成式 AI 风潮席卷的当下,相信大家已经对 AI 日新月异的知识学习、运用、推理和创造力刮目相看,很可能担心的是一个普通企业能否支撑得起 ChatGPT 这样的生成式语言大模型(Large Language Model,LLM)。确实,之所以 ChatGPT 有这样的神奇表现,离不开它所基于的模型的 “大”,比如 GPT3 有 1750 亿个参数,而 GPT4 传说的参数量还要再大上 10 倍以上。这样做是为了大模型的知识承载量能达到所谓的 “涌现能力”(Emergent Abilities),即当越过一定的参数量后,AI 就象被点化顿悟了一样,迸发出惊人的推理和创造力,具备了当初训练时完全没有的能力,让 AI 能写代码、能通过律师考试、能创造诗词绘画……。但这样规模的模型需要数十个机架、数百台高端服务器和数千块高端 GPU 花费数星期、并且有海量的优质训练数据才能得到,这些显然不是一个普通企业能够承受的。于是有些企业选择使用公有云提供的大模型,但更多的企业对合规和安全敏感,无法接受把数据交给云端。好在类似的多个大模型都有开源版本,企业下载下来也就几百个 G,并且效果已经追上了 GPT3、Claude-v1 这样的著名商用模型【1】。接下来的问题是这些本地化模型的使用。首先资源倒不是一个非常严重的问题,即便是用千亿参数级别模型按要求生成结果(称为 “推理”),在千人每人日均访问量为 10 次这种典型企业应用规模下,1 台拥有几块好 GPU 的服务器也足以胜任了【2】,麻烦的是推理过程中的 “幻觉”(Hallucination)。所谓幻觉通俗的说就是在知识缺乏下的 “瞎编”。下图就是大模型在不了解笔者本人经历的前提下编织出来的笔者简历,看得出它被训练成非常想讨好人类,但这样的简历还是令笔者直出冷汗。
当然一些比较优秀的大模型能够在相当程度上抑制幻觉,比如 ChatGPT3.5 和 4 的版本都能对笔者的类似提问给出 “不知道” 一类的回答。
但即便 AI 去除了幻觉,在 IT 运维中缺乏相关知识,特别是对企业实际运行系统缺乏相关了解,仍然没有任何利用价值。解决方案是让大模型接受 “再教育”,即让已经具备有相当通识水准的基础模型获得特定领域的新知识。最自然的方法就是再次训练基础模型,让调整后的大模型参数能反映对新知识的理解,我们称之为对基础模型的 “微调”(Fine-tuning)。微调的训练量虽然远小于从零开始训练一个基础大模型,但动辄万亿级别的参数量对于大多数企业还是一个无法承受的代价,于是各种参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)技术应运而生,比如适配器(Adapter)技术、前缀调优(Prefix-tuning),以及著名的 LoRA(Low-Rank Adaptation,低秩矩阵适配)等等。以 LoRA 为例,我们可以不直接训练基础大模型本身,而是去训练一个规模较小的秩分解矩阵(低秩矩阵),然后注入到大模型 Transformer 的每一层,让推理性能和结果与做了全量微调的效果相近,甚至一些特殊场景效果更好,但训练的代价却大幅度降低。但微调技术对于企业运维这一特定场景下还是有如下短板:• 融合幻觉问题:微调能增加对新知识的理解,但由于 Transformer 参数的可解释程度低,无法有效的区分新旧知识,处理不当就容易造成 “融合式” 幻觉,比如前面的例子里将我新加入的个人经历和模型已掌握的简历融合,很可能会形成一个一半是我一半是别人的简历。• 知识权限问题:很多企业里对知识的访问权限控制是非常严格的,不同级别的管理员应当只能授权不同级别的知识库,而在微调后的统一大模型里,所有知识都是 “融会贯通” 的,很难根据不同用户级别对答案所包含的知识做精确的内容定位和筛选。•技术难度问题:虽然参数高效微调PEFT技术能大大降低训练代价,但设计一个效果好、成功率高的PEFT方案对一般非AI技术企业而言还是有很大挑战的。•知识更新问题:企业运维知识更新相对其他领域更为频繁,而因为参数的不可解释性,哪怕是一个微小的知识更新,都需要重新微调整个模型,因而即便是PEFT,频繁训练的代价对一般企业而言也是难以承受的。
思科架构师和高级服务团队针对以上问题给出了本地知识库高效挂接的最佳实践,可以将高级服务团队的多年运维案例库、官方验证的最佳设计、思科的各类产品的技术实践、运维指南等等宝贵知识结合到生成式大模型中,同时集成思科 FSO 提供的丰富模型化遥测和异常洞察,让用户能够最大化利用生成式 AI 的涌现效应实现 “全栈专家亲临现场” 的效果。下一期我们将为您带来相关的详细介绍,敬请期待。【1】https://lmsys.org/blog/2023-06-22-leaderboard/ 






